工作分享——部署LangChain开发环境并运行demo
工作分享——部署LangChain开发环境并运行demo
基于Docker部署LangChain开发环境
Dockerfile
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 1. 使用官方Python 3.11镜像
FROM python:3.11-slim
# 2. (可选) 安装 uv 来加速
# 您甚至可以换回 "pip install --no-cache-dir ..."
RUN pip install uv
# 3. 设置工作目录
WORKDIR /app
# 4. 复制依赖文件
COPY requirements.txt .
# 5. 安装依赖
# 这就是一个最简单、只管隔离的安装命令
# --no-cache-dir 确保缓存不会被打包进镜像,保持镜像苗条
RUN uv pip install --system --no-cache-dir -r requirements.txt
# 6. 复制您的代码
# 注意:我们仍然使用 docker-compose 的 "volumes" 来覆盖它
# 这使得您在WSL中的代码可以实时同步
COPY ./src /app/src
# 7. 保持容器运行
CMD ["tail", "-f", "/dev/null"]
docker-compose.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
services:
langchain_dev:
# 依然使用当前目录的 Dockerfile 构建
build: .
image: langchain-env:latest
env_file: .env # 会将.env文件中的变量自动export为环境变量
# !!! 核心功能:挂载卷 !!!
# 您的 WSL 代码 ('.') 实时同步到容器的 /app
volumes:
- .:/app
# Jupyter Lab 端口映射
ports:
- "8888:8888"
# 保持容器在前台运行
stdin_open: true
tty: true
start-jupyter.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
#!/bin/bash
# 启动Docker容器中的Jupyter Lab脚本
# 该脚本会自动构建镜像、启动容器并在容器中启动Jupyter Lab
echo "🚀 正在启动 Jupyter Lab..."
# 检查Docker是否正在运行
if ! docker info > /dev/null 2>&1; then
echo "❌ Docker 未运行,请先启动 Docker"
exit 1
fi
# 检查是否提供了build参数
if [ "$1" = "build" ]; then
echo "📦 正在构建和启动容器..."
docker-compose up -d --build
else
echo "📦 正在启动容器(不重新构建)..."
docker-compose up -d
fi
# 等待容器完全启动
echo "⏳ 等待容器启动..."
sleep 5
# 检查容器是否正常运行
if ! docker-compose ps | grep -q "Up"; then
echo "❌ 容器启动失败"
exit 1
fi
echo "✅ 容器启动成功"
# 在容器中启动Jupyter Lab
echo "🔥 正在启动 Jupyter Lab..."
docker-compose exec -d langchain_dev bash -c "jupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root --NotebookApp.token='' --NotebookApp.password='' > jupyter.log 2>&1"
# 等待Jupyter Lab启动
sleep 5
# 检查Jupyter Lab是否在运行 pgrep -f jupyter-lab不可用
if docker-compose exec langchain_dev bash -c "grep -l 'jupyter-lab' /proc/[0-9]*/cmdline 2>/dev/null | wc -l" > /dev/null 2>&1; then
echo "✅ Jupyter Lab 启动成功!"
echo "🌐 访问地址: http://localhost:8888"
echo "📊 日志文件: docker-compose exec langchain_dev cat jupyter.log"
else
echo "❌ Jupyter Lab 启动失败"
echo "📊 查看日志: docker-compose exec langchain_dev cat jupyter.log"
exit 1
fi
echo ""
echo "📋 常用命令:"
echo " 查看日志: docker-compose exec langchain_dev cat jupyter.log"
echo " 停止服务: ./stop-jupyter.sh"
echo " 进入容器: docker-compose exec langchain_dev bash"
pgrep命令替换
1
2
# pgrep -f jupyter-lab 中 pgrep在基础linux镜像中并没有安装,改为使用更底层的grep
grep -l 'jupyter-lab' /proc/[0-9]*/cmdline 2>/dev/null | wc -l"
命令分解:
/proc/[0-9]*/cmdline:- Linux 内核会把每个正在运行的进程(PID)作为一个目录放在
/proc下,例如/proc/123。 [0-9]*是一个通配符,表示“所有纯数字的目录”。cmdline是每个 PID 目录下的一个特殊文件,它包含了启动该进程的完整命令 (这正是pgrep -f要搜索的地方)。
- Linux 内核会把每个正在运行的进程(PID)作为一个目录放在
grep -l "jupyter-lab" ...:grep在所有这些cmdline文件中搜索 “jupyter-lab” 字符串。-l(小写的L) 是关键:它告诉grep不要打印匹配的*内容*,而是打印匹配的*文件名*。- 输出会是这样:
/proc/123/cmdline
2>/dev/null:- 在搜索时,有些进程可能会瞬间消失,导致
grep报“文件未找到”的错误。2>/dev/null会把这些错误信息重定向并丢弃,保持输出干净。
- 在搜索时,有些进程可能会瞬间消失,导致
wc -l:- 计算行数,不为0则说明有进程
requirements.txt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# LangChain核心库
langchain>=1.0.0
langchain-core>=1.0.0
# LangChain集成包
langchain-openai>=1.0.0
langchain-anthropic>=1.0.0
# 常用工具和依赖
python-dotenv>=1.0.0
pydantic>=2.0.0
requests>=2.31.0
# Jupyter Lab
jupyterlab>=4.0.0
ipykernel>=6.25.0
jupyterlab-code-formatter<=3.0.2
jupyterlab-lsp>=4.2.0
jupyterlab-widgets>=3.0.0
# 输出美化工具
rich>=13.0.0
prettytable>=3.0.0
tabulate>=0.9.0
# 数据可视化增强
plotly>=5.0.0
seaborn>=0.12.0
matplotlib>=3.7.0
# 代码质量工具
black>=23.0.0
isort>=5.12.0
flake8>=6.0.0
Demo代码
Tools
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def search(query: str) -> str:
"""Search for information."""
return f"Results for: {query}"
@tool
def get_weather(location: str) -> str:
"""Get weather information for a location."""
return f"Weather in {location}: Sunny, 72°F"
tools = [search, get_weather]
Agents
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
import os
from rich import print
# 1. 实例化模型
model_kimi_k2 = ChatOpenAI(
openai_api_key=os.getenv('KIMI_API_KEY'), # Kimi API-Key
openai_api_base=os.getenv('KIMI_API_BASE_URL'),
model="kimi-k2-0905-preview", # 也可以选 moonshot-v1-8k / 32k
temperature=0.1,
max_tokens=1000,
timeout=30
)
model_kimi_v1_8k = ChatOpenAI(
openai_api_key=os.getenv('KIMI_API_KEY'), # Kimi API-Key
openai_api_base=os.getenv('KIMI_API_BASE_URL'),
model="moonshot-v1-8k", # 也可以选 moonshot-v1-8k / 32k
temperature=0.1,
max_tokens=1000,
timeout=30
)
agent = create_agent(model_kimi_v1_8k, tools=tools)
result = agent.invoke(
{"messages": [{"role": "user", "content": "What's the weather in San Francisco? aha"}]}
)
print(result)
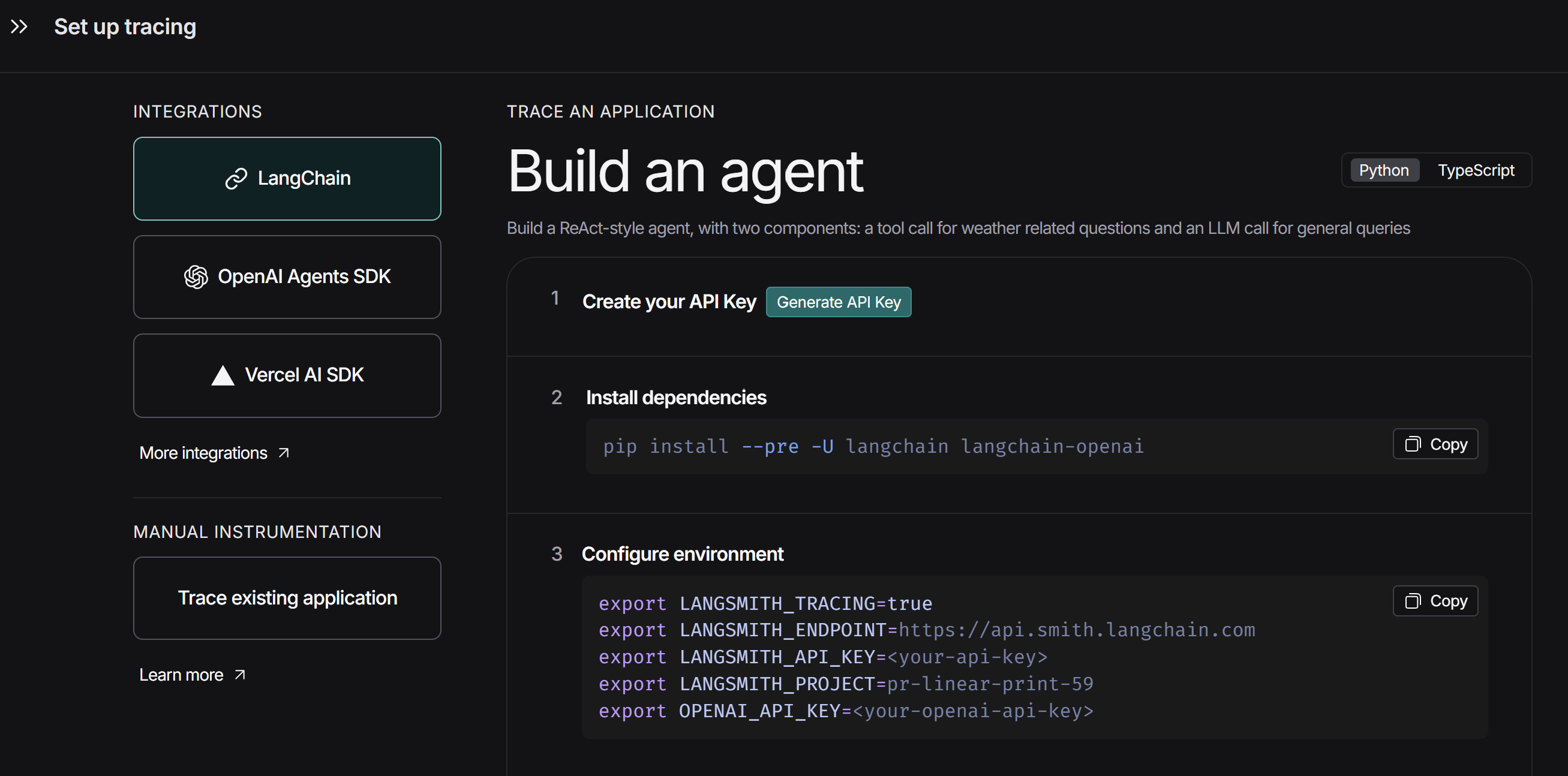
连接LangSmith
- 登录:https://smith.langchain.com/
- Home
- Set up tracing
- 将Configure environment复制到.env文件中即可
Python相关
读取环境变量
1
2
3
4
5
6
7
8
9
10
11
12
import os
# 1. 实例化模型
model_kimi_k2 = ChatOpenAI(
# python读取环境变量
openai_api_key=os.getenv('KIMI_API_KEY'),
openai_api_base=os.getenv('KIMI_API_BASE_URL'),
model="kimi-k2-0905-preview",
temperature=0.1,
max_tokens=1000,
timeout=30
)
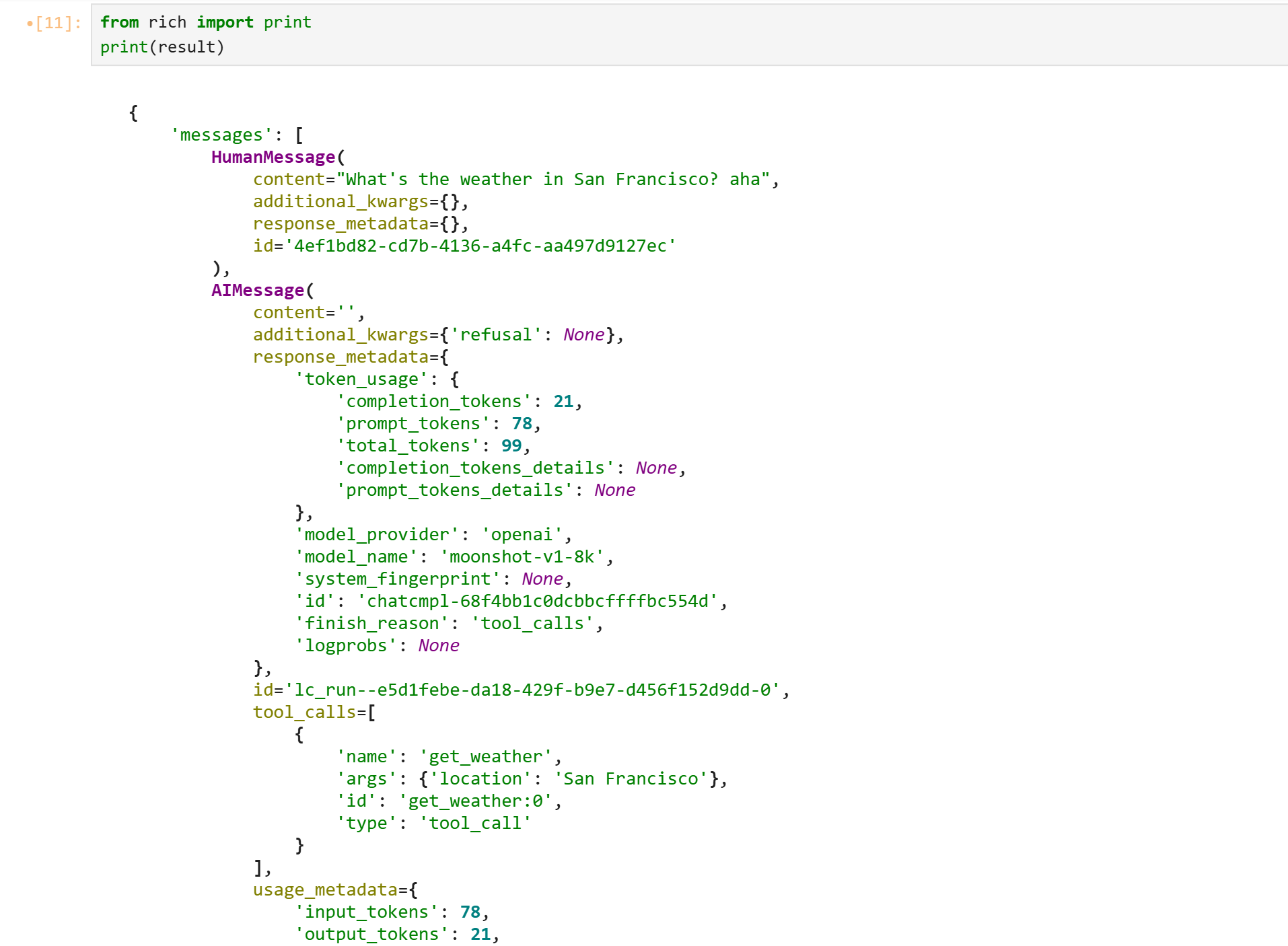
Rich库美化Jupyter-lab输出
1
2
3
4
5
from rich import print
result = agent.invoke(
{"messages": [{"role": "user", "content": "What's the weather in San Francisco? aha"}]}
)
print(result)
本文由作者按照 CC BY 4.0 进行授权